내 첫 블로그인 Google Blog를 사용하다가, 다른 blog가 더 깔끔하다는 느낌을 많이 받았다.
물론, 내가 html과 css의 고수였다면 구글블로그로 이쁘게 만들었을 수도 있었겠지만, 사람들이 사용하는 다른 blog 플랫폼은 어떤지 궁금해서 media 블로그를 시작하게 되었고, media 블로그 특유의 깔끔함이 너무 좋아 블로그를 이사하게 되었다.
https://medium.com/sjk5766
비밀번호 없이 리눅스 SSH 접속하기
현재 공부중인 docker 관련해서 특정 호스트에 ssh 패스워드 질의 없이 접속 후, 작업하는 과정이 예상되어, 패스워드 질의 없이 ssh 접속하는 법을 알아보았다. 방법은 간단한데 자꾸 실패를 반복.. 한 시간은 넘게 시간을 소모한것 같다.
ssh 명령을 입력하는 PC를 client, ssh 명령으로 접속할 PC를 서버라고 부르겠다.
client가 서버로 ssh 접속 시 보통은 아래와 같이 패스워드를 물어본다. 패스워드를 물어보지 않고 접속하는 방법을 아래서부터 알아본다.

패스워드가 아닌 인증서로 client와 server가 인증할 수 있도록 rsa key를 만든다. ssh-keygen 명령어로 key를 생성하며 만들어진 id_rsa는 비밀키, id_rsa.pub은 공개키가 된다.
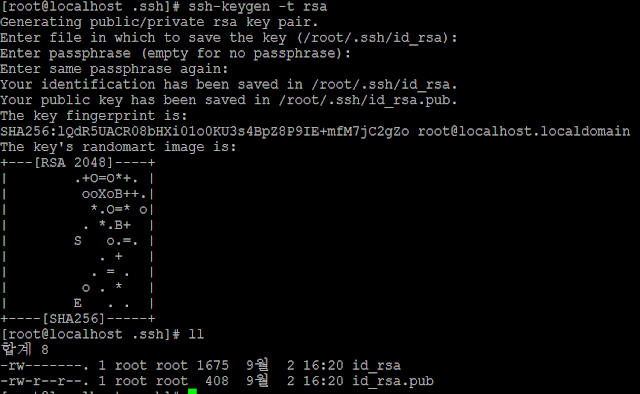
client에서 만든 id_rsa.pub 파일을 server로 옮긴 후 authorized_keys로 변경한다.
옮기는 방법에는 2가지가 있다. scp 명령어로 옮긴 후 파일의 이름을 바꾸는 방법으로 아래 그림과 같다. client에서는 scp 명령으로 id_rsa.pub (공개키)를 server로 옮긴다. server에서는 받은 id_rsa.pub 파일 내용 그대로 authorized_keys 파일을 만든다.
 < client에서 scp 명령 >
< client에서 scp 명령 >
 < id_rsa.pub 파일로 authorized_keys 파일 생성 >
< id_rsa.pub 파일로 authorized_keys 파일 생성 >
두 번쨰 방법으론 나도 이번에 처음 본건데 client key를 server의 authorized_keys 파일로 만들어주는 명령어가 있다. 다음의 그림과 같다.
 < client에서 ssh-copy-id 명령으로 key 전달 >
< client에서 ssh-copy-id 명령으로 key 전달 >
 < server에서는 authorized_keys 파일이 생성됨 >
< server에서는 authorized_keys 파일이 생성됨 >
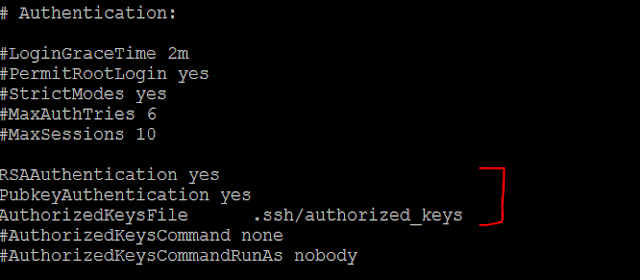
/etc/ssh/sshd_config 파일을 열어보면 ssh 관련된 설정 값이 있다. 아래와 같이 빨간색 부분들이 주석처리 되어있다면 해제하고 저장한다. 그리고 service sshd restart 명령으로 ssh 데몬을 재시작한다.
ssh 명령을 입력하는 PC를 client, ssh 명령으로 접속할 PC를 서버라고 부르겠다.
client가 서버로 ssh 접속 시 보통은 아래와 같이 패스워드를 물어본다. 패스워드를 물어보지 않고 접속하는 방법을 아래서부터 알아본다.

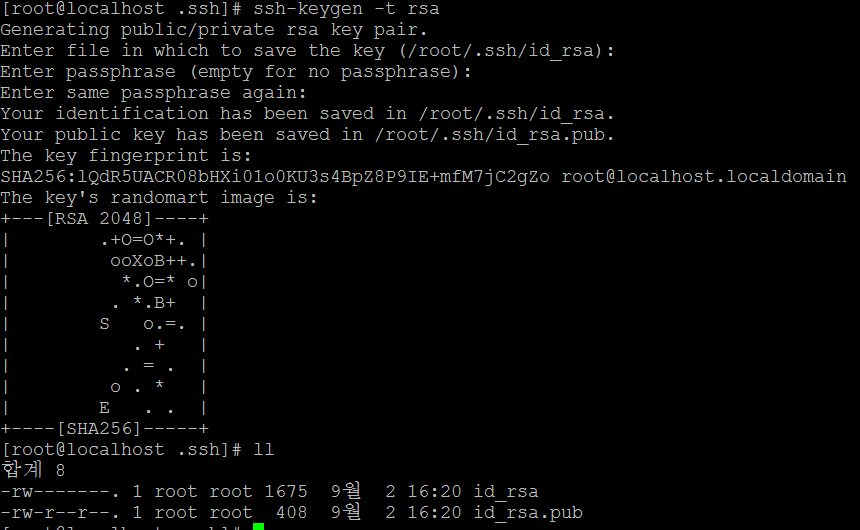
1. rsa key 쌍 생성
패스워드가 아닌 인증서로 client와 server가 인증할 수 있도록 rsa key를 만든다. ssh-keygen 명령어로 key를 생성하며 만들어진 id_rsa는 비밀키, id_rsa.pub은 공개키가 된다.
2. server .ssh 폴더에 authorized_keys 파일 생성
옮기는 방법에는 2가지가 있다. scp 명령어로 옮긴 후 파일의 이름을 바꾸는 방법으로 아래 그림과 같다. client에서는 scp 명령으로 id_rsa.pub (공개키)를 server로 옮긴다. server에서는 받은 id_rsa.pub 파일 내용 그대로 authorized_keys 파일을 만든다.


두 번쨰 방법으론 나도 이번에 처음 본건데 client key를 server의 authorized_keys 파일로 만들어주는 명령어가 있다. 다음의 그림과 같다.


3. /etc/ssh/sshd_config 파일 수정
/etc/ssh/sshd_config 파일을 열어보면 ssh 관련된 설정 값이 있다. 아래와 같이 빨간색 부분들이 주석처리 되어있다면 해제하고 저장한다. 그리고 service sshd restart 명령으로 ssh 데몬을 재시작한다.

4. client 접속 확인
이제 모든 준비는 끝났으니 client에서 ssh root@서버IP 로 접속하면 password 인증 없이 접속 되는 것을 확인할 수 있다.

AWS 란
최근 docker 를 공부중인데, 공부하면서 AWS(Amazon Web Service), 마이크로 소프트의 azure 들을 많이 접하면서 AWS에 간단하게 본 것들을 정리하겠다.
1. 회사 내부에 직접 서버를 운영
2. 호스팅을 이용
3. IDC 코로케이션 서비스 이용
호스팅 서비스는 월 단위로 계약금을 지불하고 오랫동안 계약시 할인되는 형태로, 선불 지급이라 부담이 큰 특징이 있다.
IDC 코로케이션은 구매 및 준비해놓은 서버를 IDC 센터에 두고 서비스를 운영하는 방식으로, 빠른 네트워크를 사용할 수 있으며 물리적으로 안전하지만, 직접 서버를 들고 가 구축 및 서비스 제공까지 시간이 걸린다는 점, 또한 비싼 비용역시 단점에 속한다.
서버를 어떻게 운영하였는가
기존에 서버를 운영하려면 아래와 같이 3가지 방법이 있었을 것이다.
1. 회사 내부에 직접 서버를 운영
2. 호스팅을 이용
3. IDC 코로케이션 서비스 이용
호스팅 서비스는 월 단위로 계약금을 지불하고 오랫동안 계약시 할인되는 형태로, 선불 지급이라 부담이 큰 특징이 있다.
IDC 코로케이션은 구매 및 준비해놓은 서버를 IDC 센터에 두고 서비스를 운영하는 방식으로, 빠른 네트워크를 사용할 수 있으며 물리적으로 안전하지만, 직접 서버를 들고 가 구축 및 서비스 제공까지 시간이 걸린다는 점, 또한 비싼 비용역시 단점에 속한다.
AWS (Amazon Web Service) 란
- Amazon 에서 제공하는 클라우드 서비스 플랫폼으로 클릭 몇 번으로 가상화 서버를 구축하고 서비스를 제공받을 수 있다.
왜 인기를 얻었는가?
기존의 서버를 운영하던 방식 3가지 (직접 운영 / 호스팅 / 코로케이션)보다 무엇이 좋길래 AWS가 그렇게 언급되는 걸까?
AWS 사용으로 얻을 수 있는 장점은 아래와 같다.
1. 빠르게 서버를 구축하고 서비스 제공이 가능하다.
2. 서버를 늘리거나 부하 분산이 자동으로 지원되므로 변화에 유연하게 대처가 가능
3. 한 시간 단위로 지불하므로, 사용한만큼 돈을 지불하면 된다.
4. 혼자서 모든 인프라를 구축 및 운영할 수 있다.
결국 시간, 비용적으로 AWS를 쓰는게 훨씬 효율적이라는 사실 ~!!
알고리즘 평가방법
알고리즘이란 어떤 문제를 해결하기 위한 절차와 방법이다.
이왕 문제를 해결할 거면, 좋은 알고리즘을 쓰면 좋다는데는 이견이 없을 것이다.
그렇다면 좋은 알고리즘은 무엇인가? 어떻게 좋다는 것을 알 수 있을까?
본 글에서는 알고리즘 평가요소, 수학적 알고리즘 평가방법에 대해 끄적여 보겠다.
2. 공간의 효율성 : 얼마나 메모리를 적게 쓰느냐?
3. 코드의 효율성 : 프로그래머 입장에선 가독성, 컴퓨터 입장에선 얼마나 컴파일러와 하드웨어에 최적화 되어 있냐?
3가지 평가요소 중 가장 중요시되는 평가요소는 시간의 효율성이다.
하드웨어가 좋아지면서 공간의 효율성은 비중이 상대적으로 낮아졌으며, 실제로 프로그램이 구동하면서 잡는 메모리를 측정해야하는 어려움이 있다. 코드의 효율성은 프로그래밍 언어에 따라 달라지므로 객관적인 지표가 되기 힘들다.
최선의 경우는 0번쨰 인덱스에서 바로 데이터를 찾는 경우다. 하지만 알고리즘 평가하는데 이는 생각할 필요가 없다. 대부분의 알고리즘은 최선의 경우엔 만족할만한 성능을 보인다.
평균의 경우는, 평균적인 경우를 계산하는게 쉽지 않다. 분석에 필요한 여러가지 시나리오와 현실적인 데이터를 구성해야 하는 문제가 존재한다.
최악의 경우는, 알고리즘 평가방법에 가장 많이 채택되며, 적어도 이정도의 성능은 보장한다 를 보여준다.

방법에는 빅-오 표기법, 오메가 표기법, 세타 표기법이 있으며 알고리즘 성능 평가 방법 중 가장 많이 사용하는 방법은 빅-오 표기법이다. 오메가, 세타 표기법에 대해선 다루지 않는다.
빅-오 표기법은 알고리즘 성능을 평가할 때, 최악의 성능을 채택한다. 빅-오 표기법의 수학적 정의는 아래와 같다.
 (뜬금없지만, 구글블로그에 수식을 자꾸 넣으려니 화가난다....)
(뜬금없지만, 구글블로그에 수식을 자꾸 넣으려니 화가난다....)
예를 들어 f(n) = 4n^2 + 100 , g(n) = n^2 이라고 하자. f(n) <= Cg(n)을 만족시키면 된다.
만약 C가 100이라면 즉, 4n^2 + 100 <= 100n^2 가 되며, n이 10일 경우 식을 만족하게 된다. 즉 두 개의 상수 C=100, K=10 이 존재하므로 f(n) = 4n^2 + 100의 빅-오는 n^2 이다.
빅-오의 수학적 정의 및 증명에 따라 f(n) = 4n^2 + 100에서 4를 곱하고 100을 더하는 것은 큰 의미가 없다는 말이다. 어떤 시간 복잡도 함수 T(n)이 존재할 때, 빅-오의 연산은 다음과 같다.
T(n) = n^2 + 2n + 1 ==> O(n^2)
T(n) = 999n^3 ==> O(n^3)
빅-오에는 대표적인 표기가 존재하며, 각 표기를 아래 그래프에서 보여준다. 가로축 n은 데이터 갯수 이며, 세로축은 연산횟수의 증가 패턴이다.

이왕 문제를 해결할 거면, 좋은 알고리즘을 쓰면 좋다는데는 이견이 없을 것이다.
그렇다면 좋은 알고리즘은 무엇인가? 어떻게 좋다는 것을 알 수 있을까?
본 글에서는 알고리즘 평가요소, 수학적 알고리즘 평가방법에 대해 끄적여 보겠다.
알고리즘 평가요소
1. 시간의 효율성 : 얼마나 빠르냐?2. 공간의 효율성 : 얼마나 메모리를 적게 쓰느냐?
3. 코드의 효율성 : 프로그래머 입장에선 가독성, 컴퓨터 입장에선 얼마나 컴파일러와 하드웨어에 최적화 되어 있냐?
3가지 평가요소 중 가장 중요시되는 평가요소는 시간의 효율성이다.
하드웨어가 좋아지면서 공간의 효율성은 비중이 상대적으로 낮아졌으며, 실제로 프로그램이 구동하면서 잡는 메모리를 측정해야하는 어려움이 있다. 코드의 효율성은 프로그래밍 언어에 따라 달라지므로 객관적인 지표가 되기 힘들다.
최선, 평균, 최악의 경우?
모든 알고리즘들은 행복할 떄와 우울할 떄가 있다. 이를 전문용어로 최선의 경우, 최악의 경우라고 한다. 100개의 데이터를 배열에 저장하고, 특정 데이터를 찾는 알고리즘이 있다고 하자.최선의 경우는 0번쨰 인덱스에서 바로 데이터를 찾는 경우다. 하지만 알고리즘 평가하는데 이는 생각할 필요가 없다. 대부분의 알고리즘은 최선의 경우엔 만족할만한 성능을 보인다.
평균의 경우는, 평균적인 경우를 계산하는게 쉽지 않다. 분석에 필요한 여러가지 시나리오와 현실적인 데이터를 구성해야 하는 문제가 존재한다.
최악의 경우는, 알고리즘 평가방법에 가장 많이 채택되며, 적어도 이정도의 성능은 보장한다 를 보여준다.

알고리즘의 수학적 성능 평가 방법
방법에는 빅-오 표기법, 오메가 표기법, 세타 표기법이 있으며 알고리즘 성능 평가 방법 중 가장 많이 사용하는 방법은 빅-오 표기법이다. 오메가, 세타 표기법에 대해선 다루지 않는다.
빅-오 표기법은 알고리즘 성능을 평가할 때, 최악의 성능을 채택한다. 빅-오 표기법의 수학적 정의는 아래와 같다.

예를 들어 f(n) = 4n^2 + 100 , g(n) = n^2 이라고 하자. f(n) <= Cg(n)을 만족시키면 된다.
만약 C가 100이라면 즉, 4n^2 + 100 <= 100n^2 가 되며, n이 10일 경우 식을 만족하게 된다. 즉 두 개의 상수 C=100, K=10 이 존재하므로 f(n) = 4n^2 + 100의 빅-오는 n^2 이다.
빅-오의 수학적 정의 및 증명에 따라 f(n) = 4n^2 + 100에서 4를 곱하고 100을 더하는 것은 큰 의미가 없다는 말이다. 어떤 시간 복잡도 함수 T(n)이 존재할 때, 빅-오의 연산은 다음과 같다.
T(n) = n^2 + 2n + 1 ==> O(n^2)
T(n) = 999n^3 ==> O(n^3)
빅-오에는 대표적인 표기가 존재하며, 각 표기를 아래 그래프에서 보여준다. 가로축 n은 데이터 갯수 이며, 세로축은 연산횟수의 증가 패턴이다.

해시 테이블 (Hash Table)
해시 테이블은 key-value 형식으로 데이터를 저장하는 자료구조로 데이터 탐색 시, 빅-오 O(1)의 성능을 낼 수 있다.
자료구조 측면에서 해시 테이블, 맵, 사전은 용어의 차이일 뿐 동일하다.
왜 해시 테이블이지? 해시가 뭔데?
해시 테이블은 key를 해시 함수를 거쳐 좁은 범위의 키로 생성하여 테이블에 저장하는 구조이다. 우리가 해시 테이블에서 데이터를 주세요! 라고 던지는게 데이터가 key이고 해시 함수를 거쳐 만들어지는 해시 테이블이 실제 관리하는 key를 해시 값, 이러한 맵핑 과정을 해싱이라고 한다.
해시 테이블의 정의를 다시 말해보면, 해싱된 키와 맵핑되는 데이터를 저장한 자료구조라고 할 수 있다.

(출처 - 위키디피아)
수 많은 key들이 해시 함수를 거치면, 동일한 값이 나올 수 있으며, 이를 충돌(collision)이 라고 한다. 아래 글에선 충돌을 해결하기 위한 몇가지 방안들을 소개한다.
열린 어드레스 방법 (Open Addressing method)
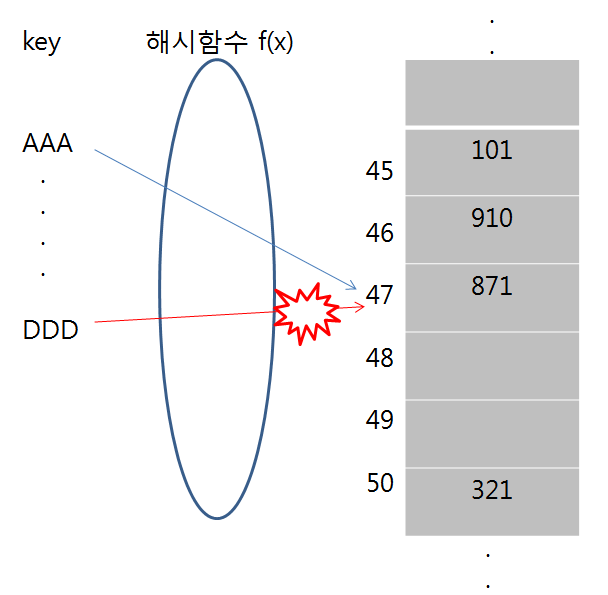
1. 선형 조사법
아래 그림에서 key AAA가 해시 테이블에 먼저 데이터를 저장하였고, 뒤 이어 key DDD의 해시 값이 충돌하게 된다. 선형조사법은 바로 옆의 자리가 비었는지 확인 후 비어있으면 그 자리에 데이터를 저장한다. 즉, 그림에선 48 부분에 데이터를 저장한다.
선형 조사법에서 데이터를 찾는 순서는 f(k) + 1 -> f(k) + 2 -> f(k) + 3 -> .... 순으로 진행 된다.
선형 조사법은 클러스터 현상, 즉 특정 영역에 데이터가 몰리는 현상이 발생할 수 있다.
이를 완화 하기위해 충돌 발생 지점에서 먼 곳에서 빈 공간을 찾아보자 라는 아이디어로 이차조사법이 나왔다.
2. 이차 조사법
선형 조사법을 알았다면 이차 조사법은 매우 쉽다. 말 그대로 공간을 좀 더 멀리찾는다. 충돌 발생 시 이차 조사법의 조사 순서는 다음과 같이 전개된다.
f(k) + 1^2 -> f(k) + 2^2 -> f(k) + 3^2 -> ....
3. 이중 해시
이차 조사법은 선형 조사법 보다는 클러스터 현상을 완화시키지만, 해시 값이 같으면 빈 공간을 찾기 위해 접근하는 위치가 항상 동일하다. 이를 해결하기 위해 이중 해시 방법이 나왔다.이중 해시에서는 두 가지 해시 함수가 존재한다.
첫 번쨰 해시 함수 : key를 해싱하는 과정에서 필요한 해시 함수
두 번쨰 해시 함수 : 충돌이 발생 시 몇 칸 뒤가 비었는지 살피기 위한 함수
이중 해시를 사용할 경우, 키가 다르면 빈 공간을 찾기위해 건너뛰는 길이도 달라 클러스터 현상의 발생 확률을 현저히 낮출 수 있다.
체이닝
체이닝은 닫힌 어드레스 방법으로, 충돌이 발생해도 자신의 자리에 저장하는 방법이다.
즉 동일한 해쉬 값에 대해 여러 값이 저장 될 수 있다.
아래 그림을 보자. AAA는 먼저 해시 테이블에 871이란 데이터를 저장한다. 뒤이어 DDD가 충돌이 발생하는데, 연결리스트를 이용해 동일한 45번 자리에 데이터를 연결시켜 저장한다.

정렬 알고리즘 Part2
Part2 에서는 복잡하지만 효율적인 정렬 알고리즘을 다룬다.
힙 정렬, 병합 정렬, 퀵 정렬 알고리즘을 다루려 했으나..
힙 정렬은 자료구조 힙의 특성을 이용한 정렬로, 힙에 데이터를 추가하는 과정에서 정렬된 데이터가 만들어지므로 딱히 쓸게 없다. (자료구조 힙이란? - https://sjkitpro.blogspot.com/2018/07/heap.html)
병합 정렬은.. 간신히 알고리즘을 이해하고 서적을 참고하여 소스를 짯으나, 완전히 이해하지 못한 것 같아 추후에 다시 공부할 때 이 부분을 업데이트 하겠다.
정렬 Part2 지만 퀵 정렬 하나만 다루는 슬픔....




힙 정렬, 병합 정렬, 퀵 정렬 알고리즘을 다루려 했으나..
힙 정렬은 자료구조 힙의 특성을 이용한 정렬로, 힙에 데이터를 추가하는 과정에서 정렬된 데이터가 만들어지므로 딱히 쓸게 없다. (자료구조 힙이란? - https://sjkitpro.blogspot.com/2018/07/heap.html)
병합 정렬은.. 간신히 알고리즘을 이해하고 서적을 참고하여 소스를 짯으나, 완전히 이해하지 못한 것 같아 추후에 다시 공부할 때 이 부분을 업데이트 하겠다.
정렬 Part2 지만 퀵 정렬 하나만 다루는 슬픔....
퀵 정렬
퀵 정렬이 무엇인지는 아래에 나오는 그림들을 보고 이해하도록 한다. 말로는 어렵다는

퀵 정렬에서는 몇 가지 알아야 하는 용어가 있는데 하나씩 설명하겠다.
left : 정렬 대상 중 가장 왼쪽 데이터를 가리키는 이름
right : 정렬 대상 중 가장 오른쪽 데이터를 가리키는 이름
pivot : 정렬의 기준, 중심축이라는 의미
low : pivot을 제외한 가장 왼쪽 데이터를 가리키는 이름
high : pivot을 제외한 가장 오른쪽 데이터를 가리키는 이름
퀵 정렬에서 low는 오른쪽으로, high는 왼쪽으로 이동하는데 이동하는 기준은 아래와 같다.
low의 오른쪽 이동 : pivot보다 큰 값을 만날 때 까지 이동
high의 왼쪽 이동 : pivot 보다 작은 값을 만날 때 까지 이동
위에서 말한대로 low와 high가 이동하는 그림을 아래와 같은데 step 별로 설명을 담겠다.

step1 : low는 오른쪽으로 이동하다 pivot(5)보다 큰 데이터 8을 만나 멈춘다.
high는 가리키던 데이터 4가 pivot(5)보다 작아 이동하지 않는다.
step2 : low와 high의 값을 바꾼다.
step3: 다시 low는 오른쪽으로 이동하다 pivot보다 큰 데이터 6을 만나 멈춘다.
high는 왼쪽으로 이동하다 pivot보다 작은 데이터 2를 만나 멈춘다.
step4: low와 high 값을 바꾼다.
step5: 서로 이동하다 low가 high보다 큰 인덱스를 가리키는 상황. 더 이상 이동하지 않는다.
step6: pivot과 high의 값을 교환한다.
위 step 6의 데이터를 보면 pivot 값을 중심으로 왼쪽에는 pivot보다 작은 데이터가 오른쪽에서는 pivot보다 큰 데이터가 정렬된 걸 확인 할 수 있다.
나머지 정렬을 진행하기 위해 pivot을 기준으로 왼쪽과 오른쪽으로 분할한다.
분할된 왼쪽과 오른쪽에 left, right, low, high 개념을 지정하고 재귀적으로 위 과정을 반복한다.

퀵 정렬 성능평가
퀵 정렬의 시간 복잡도는 아래와 같다. (구글 블로그는 수식 추가 없나...???)
동일한 빅-오 를 갖는 다른 정렬 알고리즘에 비해 평균적으로 가장 빠른 정렬 속도를 보인다.
정렬 알고리즘 part1
정렬 알고리즘 part 1에선, 빅-오 성능 n^2인 알고리즘 들을 살펴보겠다.
쉽게 말해 알고리즘 성능이 좋지 않은 정렬 방법들을 살펴본다.
정렬 알고리즘을 항상 외우고 있을 필요는 없다고 생각한다.
허나, 필요할 때 어떤 알고리즘 이였지? 라는 질문에 대한 답을 이 글에서 찾길 바라는 마음에 정리하였다.
소스 구현 및 테스트는 따로 하였으나 본 글에는 소스를 적진 않으며, 알고리즘 설명을 위해 ppt 이미지를 많이 첨부하게 되었다.


 n개의 데이터를 버블 정렬 시킬 경우, n-1 라운드가 필요하며, 각 라운드가 끝나면 비교할 대상이 한 개씩 줄어든다. 이를 알면 아래의 성능평가를 이해할 수 있다.
n개의 데이터를 버블 정렬 시킬 경우, n-1 라운드가 필요하며, 각 라운드가 끝나면 비교할 대상이 한 개씩 줄어든다. 이를 알면 아래의 성능평가를 이해할 수 있다.





쉽게 말해 알고리즘 성능이 좋지 않은 정렬 방법들을 살펴본다.
정렬 알고리즘을 항상 외우고 있을 필요는 없다고 생각한다.
허나, 필요할 때 어떤 알고리즘 이였지? 라는 질문에 대한 답을 이 글에서 찾길 바라는 마음에 정리하였다.
소스 구현 및 테스트는 따로 하였으나 본 글에는 소스를 적진 않으며, 알고리즘 설명을 위해 ppt 이미지를 많이 첨부하게 되었다.
버블 정렬
버블 정렬은 인접한 요소들을 비교하는 방법으로 데이터를 정렬하며 각 라운드에서 최대값을 먼저 정렬하는 방법이다.
알고리즘
4개의 데이터를 정렬하기 위한 1 라운드 과정이다. 인접한 요소들을 비교해 큰 값을 뒤로 이동 시키며, 1라운드가 끝나면 가장 큰 데이터가 맨 뒤로 정렬된다.

버블 정렬의 2라운드 과정이다. 1라운드를 통해 가장 큰 값이 맨 뒤로 정렬되었으니, 나머지 3개의 데이터만 정렬하면 된다.

마지막 3라운드 과정이다. 1,2 라운드를 통해 4개의 데이터 중 가장 큰 값 두개가 맨뒤에 정렬이 되었다. 따라서 남은 2개만 비교하여 정렬의 위치를 찾으면 된다.
성능평가


선택 정렬
선택 정렬은 정렬 순서에 맞게 하나씩 선택해서 옮기는, 옮기면서 정렬이 되는 알고리즘이다. 예를 들면, 가장 작은 데이터를 선택해 첫 번째 자리로 옮기고, 두 번째로 작은 데이터를 선택해 두 번째 자리로 옮긴다.
알고리즘
아래 그림은 선택 정렬 시, 각 라운드에 따른 정렬 순서를 보여준다.
1 라운드에서는 가장 작은 값 1을 첫 번째 자리로 옮기고,
2 라운드에서는 두 번째로 작은 값 2를 두 번째 자리로 옮기며,
3 라운드에서는 세 번째로 작은 값 3을 세번째 자리로 옮긴다.
위의 버블 정렬과는 달리 각 라운드가 끝난 결과만을 보여준다. (일일히 그리기 힘들다 ㅠ)

성능평가
데이터 n개를 선택정렬 하기 위해 n-1 라운드가 필요하며, 각 라운드마다 최소 값을 찾는 루프가 존재한다. 이에 따른 성능평가는 아래와 같다.

삽입정렬
삽입 정렬은 정렬되지 않은 부분과 정렬된 부분으로 나눈다. 그리고 정렬되지 않은 부분의 각 요소를 삽입하는 과정에서 정렬이 진행된다.
그림으로 보는게 빠르다.
알고리즘
아래 그림에서 첫 번째 라운드의 정렬을 통해 정렬 된 부분과 정렬되지 않은 부분으로 나눈다. 그리고 정렬되지 않은 데이터 4, 1을 맞는 위치에 삽입함으로써 정렬을 완성한다.

성능평가
삽입 정렬도 위 정렬 알고리즘과 마찬가지로, n개의 데이터 정렬을 위해 n-1라운드가 필요하며 각 라운드마다 삽입 위치를 찾기위한 루프가 존재한다.

컴퓨터의 힙(Heap)
때는 대학생, 한참 이력서를 넣고 있던 시절, 전화면접이 있었다.
전화 면접관 : 질문 중 하나가 자료구조의 힙에 대해 설명해 보시겠어요?
나 : ?????? 힙은 메모리를 말하는게 아닌가요???????
전화 면접관 : .......(침묵)
나 : ................. (속으로 울고있음)
면접 이후, 자료구조 힙에 대해 공부하였고, 현재 자료구조 서적에서 다시금 보이길래 메모리의 힙과 자료구조 힙에 대한 설명을 담는다.


일반 이진 트리를 구현할때는 연결 리스트(링크드 리스트)를 많이 사용하는데, 힙은 배열로 구현하는 것이 원칙처럼 여겨진다. 이유는, 힙에서 데이터를 추가하면, 노드를 연결하고 데이터 값에 따른 노드의 위치조정을 해야한다. 반면 배열로 구현할 경우, 배열의 인덱스를 통해 훨씬 쉽게 구현이 되기 때문이다.
힙에서 데이터 추가 과정에 대해 상세히 설명하려면.. ppt로 그림을 여러번 그려야 되기 때문에 과감히 생략하고.. 다른 블로그를 찾아주세염 ㅎ.ㅎ........
전화 면접관 : 질문 중 하나가 자료구조의 힙에 대해 설명해 보시겠어요?
나 : ?????? 힙은 메모리를 말하는게 아닌가요???????
전화 면접관 : .......(침묵)
나 : ................. (속으로 울고있음)
면접 이후, 자료구조 힙에 대해 공부하였고, 현재 자료구조 서적에서 다시금 보이길래 메모리의 힙과 자료구조 힙에 대한 설명을 담는다.
메모리 힙(Heap)
프로그램이 실행되면 아래 그림과 같이 4개의 메모리 영역을 가지게 된다.
이중 Heap 영역은 사용자가 동적할당을 할 경우 메모리에 저장된다.
C언어에서는 malloc, java에서는 new 키워드로 Heap 영역에 메모리를 할당할 수 있다.
Heap 메모리의 해제는 C에서는 free 함수로 해제하며, java에서는 JVM에서 가비지 컬렉터가 지우는 시점에 해제된다.

자료구조의 힙(Heap)
힙은 완전 이진 트리이다. 최소 값 혹은 최대 값을 찾아내는 연산에 적합하다.
힙에는 최소 힙과 최대 힙이 있다. 최대 힙은 루트노드로 갈수록 값이 커지며, 최소 힙은 루트노드로 갈수록 값이 작아진다. ( 아래 그림 참조)

힙에서 데이터 추가 과정에 대해 상세히 설명하려면.. ppt로 그림을 여러번 그려야 되기 때문에 과감히 생략하고.. 다른 블로그를 찾아주세염 ㅎ.ㅎ........
이진 트리란
자료구조를 공부한지 꽤 지났다. 책을 다시 펴보니 선형 리스트(리스트, 스택, 큐)는 잘 이해하고 있는데 항상 비선형 리스트(트리, 그래프)는 뭔가 새롭다.








트리에 대해 공부해보자.
Q. 트리란?
- 계층적 관계를 표현하는 자료구조이다.
Q. 이진 트리란?
- 루트 노드를 중심으로 두 개의 서브 트리로 나뉘어진다.
- 나뉘어진 두 서브 트리 모두 이진 트리여야 한다.

위 그림은 이진 트리를 보여주는데, 트리에서 사용되는 용어들을 살펴보자
1. 노드 : 트리의 구성요소에 해당하는 A~E까지의 각 요소
2. 간선 : 노드와 노드를 연결하는 연결선
3. 루트 노드 : 트리 구조 최상단에 있는 A 노드
4. 단말노드 : 아래에 다른 노드가 없는 H, E, F, G 노드
5. 차수 : 한 노드에 연결된 서브 노드의 개수, 이진 트리의 차수는 2 이하.
5. 차수 : 한 노드에 연결된 서브 노드의 개수, 이진 트리의 차수는 2 이하.
6. 레벨 : 트리에서 각 층별로 숫자를 매김, A는 0레벨, B,C는 1레벨
7. 높이 : 트리의 최고 레벨을 의미한다. H는 레벨3에 속하므로 위 트리의 높이는 3이다.
8. 포화 이진 트리 : 트리의 모든 레벨이 꽉 차 있는 트리 (아래 그림 참조)

9. 완전 이진트리 : 포화 이진 트리는 아니지만 빈틈 없이 노드가 채워진 이진트리 (아래 그림참조)

트리에 저장된 모든 데이터를 출력해야 한다고 가정하자. 우선, 트리의 모든 노드를 방문해야 하는데, 이를 순회라고 한다.
트리를 순회하는 방법에는 아래와 같이 4가지가 있다.
전위 순회 : 루트노드를 먼저 방문한다.
중위 순회 : 루트노드를 중간에 방문한다.
후위 순회 : 루트노드를 마지막에 방문한다.
단계 순회 : 루트노드부터 왼쪽 노드와 오른쪽 노드를 차례대로 방문한다.
단계 순회 : 루트노드부터 왼쪽 노드와 오른쪽 노드를 차례대로 방문한다.
핵심은 루트 노드의 방문 순서이다. 글보다는 그림이 이해가 편하다.
전위 순회 방법 ( A-> B-> C)
- 루트노트를 먼저 방문하고 왼쪽부터 오른쪽 순으로 순회한다.
- 루트노트를 먼저 방문하고 왼쪽부터 오른쪽 순으로 순회한다.
중위 순회 방법 (B-> A-> C)
- 왼쪽 노드를 먼저 방문 후, 루트노드를 방문한뒤 오른쪽으로 순회한다.
- 왼쪽 노드를 먼저 방문 후, 루트노드를 방문한뒤 오른쪽으로 순회한다.
후위 순회 방법 (B-> C-> A)
- 왼쪽부터 오른쪽으로, 루트노드를 가장 마지막에 방문한다.
- 왼쪽부터 오른쪽으로, 루트노드를 가장 마지막에 방문한다.
단계 순회 방법 (A-> B-> C)
- 루트노드부터 왼쪽과 오른쪽으로 단계적으로 순회하는 방법
전위 순회와 단계 순회의 결과가 같아보이지만, 트리의 레벨을 한 단계 높인 순회 예시를 들면 이해할 것이라 믿는다.
전위 순회 방법 : A-> B-> D-> E-> C-> F-> G
단계 순회 방법 : A-> B-> C-> D-> E-> F-> G

함수형 프로그래밍
조 후임 : 함수형 프로그래밍이 뭐에여?
나 : 람다 대수를 기반으로 발전된 언어로, 변경 가능한 상태를 최대한 제거하여 사이드 이펙트를 제거하는 프로그래밍 방법이에요.
조 후임 : 잘 이해가 안가요
나 : 음 ....( 겉핥기 지식 ㅂㄷㅂㄷ..... 공부합시다)
함수형 프로그래밍은 프로그래밍 패러다임 중 하나
Q. 패러다임이란?
A. 한 시대 특정 분야의 사람들이 공유하는 이론, 법칙, 방법, 지식
Q. 프로그래밍 패러다임이란?
A. 소프트웨어 개발 과정에서 개발자들이 공유하는 이론, 법칙 방법, 지식
소프트웨어를 바라보는 관점, 설계 및 개발에 대한 방법론 (절차, 객체지향, 함수형..)
Q. 프로그래밍 언어와 패러다임의 관계?
A. 프로그래밍 언어가 프로그래밍 패러다임을 지원한다.
C++은 객체지향 언어지만, 절차지향으로도 코딩이 가능하다.
즉, 어떤 언어가 프로그래밍 패러다임의 여러 방식을 지원한다면, 우린 그 중 하나의 방법론을 택해 소프트웨어를 설계 하고 개발하는 것이다.
객체지향 프로그래밍이 뭐야? 라는 질문에 아래와 같이 대답할 수 있을 것이다.
소프트웨어 설계 및 개발 과정에서, 실세계를 모델링하는 것 처럼 소프트웨어의 각 객체를 정의하고 그 객체들간의 데이터를 전달하고 공유하는 프로그래밍 방법이야.
그렇다면... 함수형 프로그래밍은 뭔데?
잠깐 위의 객체지향 프로그래밍에 대한 설명을 떠올려보자.
클래스를 정의하고 객체 인스턴스를 생성하여 객체간의 데이터를 전달해본 사람이라면, 위의 설명을 보고 '객체지향을 간단히 설명하는 방법 중 하나' 라고 이해하고 넘어 갈 것이다.
이렇게 생각한 사람들은 상속, 오버로딩, 오버라이딩, 추상메소드와 다형성 등, 객체지향에 사용되는 많은 개념과 기법들을 이해하고 있거나 한번쯤은 들어봤을 것이다.
함수형 프로그래밍은 객체지향 프로그래밍 처럼 프로그래밍 패러다임 중 하나이다.
즉 객체지향 프로그래밍 처럼 함수형 프로그래밍도 일급 함수 객체, 고차함수, 람다대수, 클로저 등, 함수형 프로그래밍에 관련된 많은 base와 개념, 지원하는 기법들이 있다.
각각에 대해 설명하고 이해하려면 적지 않은 시간이 걸리기 때문에 본 글에서는 함수형 프로그래밍이 무엇을 중요시하는지를 살펴보자.
함수형 프로그래밍의 컨셉!!
첫 번째도..두번쨰도,, N번째도!!! 부작용 (Side effect) 을 제거하자.!!!
이것이다. 이게 함수형 프로그래밍의 가장 중요한 컨셉이다.
그렇다면 부작용은 무엇을 말하는가? 아래 코드를 보자.
int z = 10;
int functionA(int x, int y)
return x + y + z;
}
동일 입력에 대해 functionA의 출력은 변할 수 있다. (z 값에 의해)
z는 funtionA의 소스를 봐야 알 수 있는 숨겨진 입/출력이며, 함수형 프로그래밍에서는 숨겨진 입/출력을 부작용이라 부른다.
즉, 함수에서 동일 입력에 대해 동일한 출력이 나오지 않는 경우 부작용이 존재한다.
그럼 부작용은 어떻게 없앨 수 있어요? 이렇게
이제야 동일 입력에 대해 동일한 출력이 나오므로, 부작용이 존재하지 않는다.
ㅇ ㅏ...그럼 함수형 프로그래밍에선, 부작용이 없는 함수를 선언하고 호출하나 보네여
그럼 부작용이 없어서 얻는 장점이 뭔데여?????
1. 코드 분석이 용이하며 단위 테스트가 쉽다.
- 함수 내부에서 변경이 없다보니, 함수의 선언만 보고 기능을 추론하기 쉬우며 코드 분석이 쉽다.
- 동일한 입력에 동일한 출력이 나오므로 단위 테스트가 쉽다.
2. 유지보수가 용이하다.,
- 함수 내부에서 변경이 없고, 하는 기능이 명확하다 보니, 기능의 추가, 수정에서 훨씬 간단하다.
3. 기존 멀티 쓰레드 환경의 문제점이 사라진다.
- 멀티 쓰레드를 공부하다 보면, 임계영역이라고 들어보았을 것이다. 여러 쓰레드에 의해 데이터가 공유되고 의도치 않게 변경될 수 있는 코드 영역을 임계 영역이라 한다. 임계영역에 대한 적절한 처리를 하지 못할 경우 발생되는 문제는 해결하기 매우 어렵다. (이건 경험해 봐야 알 수있음 ㅂㄷㅂㄷ) 하지만 함수형 프로그래밍에선 데이터의 변경을 기피하고 제거하기 때문에 멀티 쓰레드 환경에서 문제없이 동작한다.
Q. 함수형 프로그래밍은 정말 데이터의 변경이 하나도 존재하지 않나여?
- 존재한다. 함수는 반환값을 얻어내기도 하지만, 어떤 동작을 수행하기도 때문이다. 함수형 프로그래밍에선 그런 데이터의 변경을 최대한 제거하고, 제거할 수 없을 경우엔 통제한다.
z는 funtionA의 소스를 봐야 알 수 있는 숨겨진 입/출력이며, 함수형 프로그래밍에서는 숨겨진 입/출력을 부작용이라 부른다.
즉, 함수에서 동일 입력에 대해 동일한 출력이 나오지 않는 경우 부작용이 존재한다.
그럼 부작용은 어떻게 없앨 수 있어요? 이렇게
이제야 동일 입력에 대해 동일한 출력이 나오므로, 부작용이 존재하지 않는다.
int z = 10;
int functionA(int x, int y, int z)
return x + y + z;
}
ㅇ ㅏ...그럼 함수형 프로그래밍에선, 부작용이 없는 함수를 선언하고 호출하나 보네여
그럼 부작용이 없어서 얻는 장점이 뭔데여?????
1. 코드 분석이 용이하며 단위 테스트가 쉽다.
- 함수 내부에서 변경이 없다보니, 함수의 선언만 보고 기능을 추론하기 쉬우며 코드 분석이 쉽다.
- 동일한 입력에 동일한 출력이 나오므로 단위 테스트가 쉽다.
2. 유지보수가 용이하다.,
- 함수 내부에서 변경이 없고, 하는 기능이 명확하다 보니, 기능의 추가, 수정에서 훨씬 간단하다.
3. 기존 멀티 쓰레드 환경의 문제점이 사라진다.
- 멀티 쓰레드를 공부하다 보면, 임계영역이라고 들어보았을 것이다. 여러 쓰레드에 의해 데이터가 공유되고 의도치 않게 변경될 수 있는 코드 영역을 임계 영역이라 한다. 임계영역에 대한 적절한 처리를 하지 못할 경우 발생되는 문제는 해결하기 매우 어렵다. (이건 경험해 봐야 알 수있음 ㅂㄷㅂㄷ) 하지만 함수형 프로그래밍에선 데이터의 변경을 기피하고 제거하기 때문에 멀티 쓰레드 환경에서 문제없이 동작한다.
Q. 함수형 프로그래밍은 정말 데이터의 변경이 하나도 존재하지 않나여?
- 존재한다. 함수는 반환값을 얻어내기도 하지만, 어떤 동작을 수행하기도 때문이다. 함수형 프로그래밍에선 그런 데이터의 변경을 최대한 제거하고, 제거할 수 없을 경우엔 통제한다.
Q. 함수형 프로그래밍 언어는 무엇인가?
- 부작용을 제거하고, 통제할 수 있도록 최대한 적극적으로 도와주는 언어. (Lisp, 하스켈, 클로져, 스칼라 등..)
- 부작용을 제거하고, 통제할 수 있도록 최대한 적극적으로 도와주는 언어. (Lisp, 하스켈, 클로져, 스칼라 등..)
함수형 프로그래밍의 컨셉을 아는 것과 실제로 구현하는 것은 다르다. 함수형 프로그래밍으로 개발하려면 공부해야 할 것들이 넘친다. (앞에 언급한 일급 함수 객체부터 ~~~ 줄줄)
적어도 본 글을 통해 함수형 프로그래밍은 이런 컨셉(개념을)을 가지고 있구나 라고 알 수있다면 좋겠다.
Linked List 구현 시, dummy 노드의 용도
자료구조 책에는 항상 리스트가 나오고, 서적마다 리스트를 구현하는 방법이 조금씩 다르다.
여기서 다르다는 표현은 dummy 노드를 쓰느냐 마느냐 이다.
어떤 서적은 dummy 노드를 쓰지만, 어떤 서적은 안쓰기도 하며, 또 어떤 서적은 둘 다를 다루기도 한다.
그럼 이 차이가 무엇인지 알아보자. 그림 수준에서 설명하면 아래와 같다.
위의 그림은 dummy 노드를 사용하지 않았으며 head가 바로 첫 번쨰 노드 A를 가리키고 있다.
아래의 그림은 dummy 노드를 사용한 경우로, head는 dummy 노드를 가리키고 있다.

핵심은 head가 가리키는 첫 번째 노드가 dummy 노드인지 아닌지이다.
이에 따른 리스트 추가 하는 코드의 차이를 비교해보자. (이해를 쉽게 하기 위해 tail 코드는 제외한다.)
우선 dummy 노드를 사용하지 않는 경우의 코드를 보자.
새로운 노드를 추가 할 때, 첫 번째 노드인지 판단이 필요하다.
두 번째로 dummy 노드를 사용하는 경우의 코드를 보자.
첫 번째 노드인 dummy가 추가되므로, 추가적인 판단 없이 노드를 추가한다.
둘 중 어떤 방법이 더 좋을까? 라는 질문의 답은 낼 수 없지만,
데이터 추가 작업이 많은 링크드 리스트라면 dummy 노드를 사용하는게 좀 더 효율이 좋아보인다.
여기서 다르다는 표현은 dummy 노드를 쓰느냐 마느냐 이다.
어떤 서적은 dummy 노드를 쓰지만, 어떤 서적은 안쓰기도 하며, 또 어떤 서적은 둘 다를 다루기도 한다.
그럼 이 차이가 무엇인지 알아보자. 그림 수준에서 설명하면 아래와 같다.
위의 그림은 dummy 노드를 사용하지 않았으며 head가 바로 첫 번쨰 노드 A를 가리키고 있다.
아래의 그림은 dummy 노드를 사용한 경우로, head는 dummy 노드를 가리키고 있다.

핵심은 head가 가리키는 첫 번째 노드가 dummy 노드인지 아닌지이다.
이에 따른 리스트 추가 하는 코드의 차이를 비교해보자. (이해를 쉽게 하기 위해 tail 코드는 제외한다.)
우선 dummy 노드를 사용하지 않는 경우의 코드를 보자.
새로운 노드를 추가 할 때, 첫 번째 노드인지 판단이 필요하다.
Node * head;
Node * tail;
Node * newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
if(head == NULL) // 첫 번째 노드를 삽입 할 때의 처리가 필요하다.
head = newNode;
else
tail->next = newNode;
tail = newNode;
두 번째로 dummy 노드를 사용하는 경우의 코드를 보자.
첫 번째 노드인 dummy가 추가되므로, 추가적인 판단 없이 노드를 추가한다.
Node * head;
Node * tail;
head = (Node*)malloc(sizeof(Node));
tail = head;
Node * newNode = (Node*)malloc(sizeof(Node));
newNode->data = data;
newNode->next = NULL;
tail->next = newNode; // 첫 번째 노드인지 판단할 필요 없이 바로 추가.
tail = newNode;
둘 중 어떤 방법이 더 좋을까? 라는 질문의 답은 낼 수 없지만,
데이터 추가 작업이 많은 링크드 리스트라면 dummy 노드를 사용하는게 좀 더 효율이 좋아보인다.
자바스크립트 new Object와 {} 생성 방식
아끼는 후임이 면접을 봤는데 질문 중 하나가 아래와 같았다.
자바스크립트에서 객체 생성 시, new Object와 그냥 괄호 {}를 쓰는 것의 차이는 무엇인가?
후임이 그런 질문을 받았다고 나한테 던지는데.. 어...음... 자 공부하자.
코드적으로 보면 아래와 같은 차이인데, 내부적으로 동작은 큰 차이가 없다.
obj2 = {} 로 선언하는 방식을 객체 리터럴 방식이라 한다. 내부적으로는 new Object를 호출하게 된다.
var obj1 = new Object() // new 연산자를 이용한 객체 생성
var obj2 = {} // 객체 리터럴로 객체를 생성
그렇다면 두 방식 중 사용을 권고하는 방식은 무엇일까?
답은 객체 리터럴로 객체를 생성하는 방식이다.
그 이유로는 아래와 같이 3가지가 있다. (물론 더 있을 수도 있다.)
1. 코딩하기 편하며 가독성이 좋다.
2. 속도가 빠르다. (근거자료 : https://jsperf.com/new-array-vs-literal/26)
3. 자바스크립트의 오버라이딩을 방지할 수 있다.
1번은 직관적으로 이해가 될 것이고
2번은 근거자료가 있으니 보면 성능을 알 수 있을 것이고
3번에 대해 좀 더 알아보자.
new Object에서 Object는 오버라이딩 될 수 있다. 가령 아래와 같다.
답은 객체 리터럴로 객체를 생성하는 방식이다.
그 이유로는 아래와 같이 3가지가 있다. (물론 더 있을 수도 있다.)
1. 코딩하기 편하며 가독성이 좋다.
2. 속도가 빠르다. (근거자료 : https://jsperf.com/new-array-vs-literal/26)
3. 자바스크립트의 오버라이딩을 방지할 수 있다.
1번은 직관적으로 이해가 될 것이고
2번은 근거자료가 있으니 보면 성능을 알 수 있을 것이고
3번에 대해 좀 더 알아보자.
new Object에서 Object는 오버라이딩 될 수 있다. 가령 아래와 같다.
Object = function(){
console.log("Object 오버라이딩");
};
var obj = new Object(); //Object 오버라이딩 출력
재귀 함수를 쓰는 이유
자료구조와 알고리즘에 대해 잘 알고있는가?
위 질문에 자신이 없어 최근 다시 책을 펴서 공부하고 있다.
재귀 함수 part가 나와 갑자기 궁금해서 검색을 해보았다.
몇 개의 글을 쭉 보던 중 누군가의 댓글에 꺠달음을 얻고 정리한다.
링크 : https://kldp.org/node/134556
재귀함수를 쓰는 이유
- 1. 알고리즘 자체가 재귀적으로 표현하기 자연스러울 때. (가독성 이야기)
- 2. 변수 사용을 줄여 준다.
1번은 알고 있었던 내용이나, 2번에 대한 설명은 오! 라는 감탄사를 가져다 주었다.
변수 사용을 줄여준다는건 변수가 잡는 메모리에 대한 이야기가 아니라,
mutable state (변경 가능한 상태) 를 제거하여 프로그램 오류가 발생할 수 있는 가능성을 줄인다는 이야기다.
함수형 프로그래밍에서, 함수를 일급 객체로 취급하여 함수를 인자로 전달 및 반환하여
mutable state 상태를 제거하는 것 처럼...
그리고 링크된 글에는 이러한 말이 나온다.
재귀 함수는 장점만큼 단점도 크다
재귀함수를 쓰지 않는 이유는 메모리를 많이 차지하며 성능이 반복문에 비해 느리다.
함수를 호출 시 함수의 매개변수, 지역변수, 리턴 값, 그리고 함수 종료 후 돌아가는 위치가 스택 메모리에 저장된다.
재귀함수를 쓰게되면, 함수를 반복적으로 호출하므로, 스택 메모리가 커지고, 호출하는 횟수가 많아지면 스택오버플로우가 발생할 수 있다.
또한 스택 프레임을 구성하고 해제하는 과정에서 반복문보다 오버헤드가 들어 성능도 느려진다.
다시 원점으로 돌아가서, 꼬리 재귀는 기존 재귀의 위와 같은 문제점을 해결할 수 있는 방법이다. 결론적으로 꼬리 재귀의 장점을 얻으려면 2가지가 필요하다
1. 프로그래머가 재귀를 꼬리 재귀 방식으로 개발한다.
2. 컴파일러가 꼬리 재귀 최적화를 지원해야 한다.
컴파일러가 꼬리 재귀 최적화를 지원하지 않으면, 개발자가 꼬리 재귀 방식으로 개발해도 성능 및 메모리의 이점을 얻을 수 없다.
코드적으로 보면 재귀와 꼬리재귀는 다음과 같은 형태를 가진다.
차이를 알겠는가? 일반 재귀는 함수의 마지막, return에 연산이 필요하다. (n + 함수(n-1))
꼬리 재귀는 return에 연산이 필요없다. 매개변수로 필요한 연산을 전달한다. (함수(n-1, n+acc))
여기서부터 꼬리 재귀의 이점은 컴파일러가 지원한다. 컴파일러가 꼬리 재귀를 최적화 할 수 있으면 최적화 하는 과정에서 꼬리 재귀를 반복문으로 변경한다.
따라서 기존 재귀의 문제였던 메모리와 성능에 대한 문제가 제거되는 것이다.
위 질문에 자신이 없어 최근 다시 책을 펴서 공부하고 있다.
재귀 함수 part가 나와 갑자기 궁금해서 검색을 해보았다.
재귀 함수는 왜 쓰는가?
몇 개의 글을 쭉 보던 중 누군가의 댓글에 꺠달음을 얻고 정리한다.
링크 : https://kldp.org/node/134556
재귀함수를 쓰는 이유
- 1. 알고리즘 자체가 재귀적으로 표현하기 자연스러울 때. (가독성 이야기)
- 2. 변수 사용을 줄여 준다.
1번은 알고 있었던 내용이나, 2번에 대한 설명은 오! 라는 감탄사를 가져다 주었다.
변수 사용을 줄여준다는건 변수가 잡는 메모리에 대한 이야기가 아니라,
mutable state (변경 가능한 상태) 를 제거하여 프로그램 오류가 발생할 수 있는 가능성을 줄인다는 이야기다.
함수형 프로그래밍에서, 함수를 일급 객체로 취급하여 함수를 인자로 전달 및 반환하여
mutable state 상태를 제거하는 것 처럼...
그리고 링크된 글에는 이러한 말이 나온다.
tail recursion (꼬리 재귀)
위에서 재귀 함수를 사용하는 이유, 즉 장점을 설명했는데 왜 재귀를 자주 쓰지 않을까?재귀 함수는 장점만큼 단점도 크다
재귀함수를 쓰지 않는 이유는 메모리를 많이 차지하며 성능이 반복문에 비해 느리다.
함수를 호출 시 함수의 매개변수, 지역변수, 리턴 값, 그리고 함수 종료 후 돌아가는 위치가 스택 메모리에 저장된다.
재귀함수를 쓰게되면, 함수를 반복적으로 호출하므로, 스택 메모리가 커지고, 호출하는 횟수가 많아지면 스택오버플로우가 발생할 수 있다.
또한 스택 프레임을 구성하고 해제하는 과정에서 반복문보다 오버헤드가 들어 성능도 느려진다.
다시 원점으로 돌아가서, 꼬리 재귀는 기존 재귀의 위와 같은 문제점을 해결할 수 있는 방법이다. 결론적으로 꼬리 재귀의 장점을 얻으려면 2가지가 필요하다
1. 프로그래머가 재귀를 꼬리 재귀 방식으로 개발한다.
2. 컴파일러가 꼬리 재귀 최적화를 지원해야 한다.
컴파일러가 꼬리 재귀 최적화를 지원하지 않으면, 개발자가 꼬리 재귀 방식으로 개발해도 성능 및 메모리의 이점을 얻을 수 없다.
코드적으로 보면 재귀와 꼬리재귀는 다음과 같은 형태를 가진다.
int Recursive(int n)
{
if(n==1) return 1;
return n + Recursive(n-1);
}
int Tail_Recursive(int n, int acc)
{
if(n==1) return acc;
return Tail_Recursive(n-1, n + acc );
}
차이를 알겠는가? 일반 재귀는 함수의 마지막, return에 연산이 필요하다. (n + 함수(n-1))
꼬리 재귀는 return에 연산이 필요없다. 매개변수로 필요한 연산을 전달한다. (함수(n-1, n+acc))
여기서부터 꼬리 재귀의 이점은 컴파일러가 지원한다. 컴파일러가 꼬리 재귀를 최적화 할 수 있으면 최적화 하는 과정에서 꼬리 재귀를 반복문으로 변경한다.
따라서 기존 재귀의 문제였던 메모리와 성능에 대한 문제가 제거되는 것이다.
스테이트 패턴
스테이트 패턴이란, 객체 내부 상태에 따라 객체의 행동이 바뀌는 것이다.
뽑기 기계가 있다고 하자. 사람은 이 기계에 동전을 넣고 손잡이를 돌리면 뽑기기계의 상품을 받게 된다. 기계의 입장에선 동전이 있고 없고의 상태를 가질 수 있다. (설명을 쉽게 하기 위해 행동과 상태를 제한하였다.)
위에서 동전이 있고, 없고는 상태이며, 동전을 넣고 손잡이를 돌리는건 행동이 된다.
이를 간단하게 구현해보면 아래와 같다. state 상태에 따라 동전을 넣고 손잡이를 돌리는 행동에 대해 다르게 동작한다.
위 예를 스테이트 패턴으로 바꾸어보자.
우선 행동에 대한 메소드가 들어있는 인터페이스를 정의한다. (여기선 state 인터페이스)
다음은 state를 구현하는 상태 class를 만든다. 여러 상태가 있다면, 각 상태에 해당하는 class를 구현한다.
뽑기 기계가 있다고 하자. 사람은 이 기계에 동전을 넣고 손잡이를 돌리면 뽑기기계의 상품을 받게 된다. 기계의 입장에선 동전이 있고 없고의 상태를 가질 수 있다. (설명을 쉽게 하기 위해 행동과 상태를 제한하였다.)
위에서 동전이 있고, 없고는 상태이며, 동전을 넣고 손잡이를 돌리는건 행동이 된다.
이를 간단하게 구현해보면 아래와 같다. state 상태에 따라 동전을 넣고 손잡이를 돌리는 행동에 대해 다르게 동작한다.
public class gamble {
final static int NO_COIN = 0;
final static int HAS_COIN = 1;
int state = NO_COIN; // 초기상태는 동전이 없음
public void insertCoin() {
if(state == NO_COIN) {
System.out.println('동전을 넣으셨습니다.');
state = HAS_COIN;
}
else if(state == HAS_COIN) {
System.out.println('동전이 이미 있습니다..');
}
}
public void turnHandle() {
if(state == NO_COIN) {
System.out.println('동전을 넣어주세요.');
}
else if(state == HAS_COIN) {
System.out.println('상품이 나옵니다.');
state = NO_COIN;
}
}
}
위 예를 스테이트 패턴으로 바꾸어보자.
우선 행동에 대한 메소드가 들어있는 인터페이스를 정의한다. (여기선 state 인터페이스)
다음은 state를 구현하는 상태 class를 만든다. 여러 상태가 있다면, 각 상태에 해당하는 class를 구현한다.
public class gamble {
state hasCoin;
state noCoin;
state s = noCoin; // 초기상태는 동전이 없음
public gamble() {
hasCoin = new HasCoin(this);
noCoin = new NoCoin(this);
}
public setState(State s) {
this.s = s;
}
public void insertCoin() {
s.insertCoin();
}
public void turnHandle() {
s.turnHandle();
}
// getter 메소드...
}
public interface state {
void insertCoin();
public void turnHandle();
}
public class HasCoin implements state {
gamble g;
public HasCoin(gamble g) {
this.g = g;
}
public void insertCoin() {
System.out.println('동전이 이미 있습니다..');
}
public void turnHandle() {
System.out.println('상품이 나옵니다.');
g.setState(gamble.getNoCoinState());
}
}
public class NoCoin implements state {
gamble g;
public NoCoin(gamble g) {
this.g = g;
}
public void insertCoin() {
System.out.println('동전을 넣으셨습니다.');
g.setState(gamble.getHasCoinState());
}
public void turnHandle() {
System.out.println('동전을 넣어주세요.');
}
}
템플릿 메소드 패턴
템플릿 메소드 패턴은 알고리즘을 캡슐화 한다. 이해가 안되니 아래를 보자.
Coffee와 Tea를 만드는 클래스가 있다. make()는 일련의 메소드를 모아 각 음료를 만드는 함수이다.
Coffee와 Tea 메소드를 보니 코드가 중복되는 부분이 있으며, 일단 코드에 중복이 있을 경우 디자인을 고쳐야 하지 않을까 라는 생각이 필요하다.
Beberage(음료)라는 상위 클래스를 만들었다. make 메소드는 서브 클래스마다 다르므로 추상 메소드로 선언한다. hotwater, putCup 메소드는 서브클래스로 공통으로 쓰기때문에 부모 클래스에 정의하였다. Coffee, Tea 클래스는 make 메소드를 내부에서 정의하고 알고리즘의 다른 부분들(putCoffee, putTea / putSugar, putLemon)은 서브클래스 내부에서 정의 하였다.

위의 다이어그램을 다시 생각해보자. 사실 putCoffe와 putTea는 만드는 과정 중 뜨거운 물에 넣는다는 의미에서 같은 맥락이고, addSugar, addLemon는 만들어진 음료 위에 무엇을 넣는것에서 같은 맥락이다.
따라서 putCoffee와 putTea를 putSomething, addSugar, addLemon을 addItem 으로 대체해보자. (조금 어거지다)
지금까지 한 것이 템플릿 메소드 패턴이라 할 수 있다.
Beverage의 make가 캡슐화된 알고리즘이 되며, 템플릿 메소드에서는 알고리즘의 각 단계들을 정의하며 한 개 이상의 알고리즘 단계가 서브클래스에 의해 제공될 수 있다.
처음 만든 클래스와 템플릿 메소드를 사용한 경우를 비교하면 아래표와 같다.

Coffee와 Tea를 만드는 클래스가 있다. make()는 일련의 메소드를 모아 각 음료를 만드는 함수이다.
public class Coffee {
void make() {
hotWater();
putCoffee();
putCup();
putSugar();
}
public void hotWater{
// 물을 끓인다.
}
public void putCoffee{
// 커피를 넣는다.
}
public void putCup{
// 커피를 컵에 넣는다
}
public void putSugar{
// 설탕을 넣는다.
}
}
public class Tea {
void make() {
hotWater();
putTea();
putCup();
putLemon();
}
public void hotWater{
// 물을 끓인다.
}
public void putTea{
// 차를 넣는다.
}
public void putCup{
// 차를 컵에 넣는다
}
public void putLemon{
// 레몬을 넣는다.
}
}
Coffee와 Tea 메소드를 보니 코드가 중복되는 부분이 있으며, 일단 코드에 중복이 있을 경우 디자인을 고쳐야 하지 않을까 라는 생각이 필요하다.
Beberage(음료)라는 상위 클래스를 만들었다. make 메소드는 서브 클래스마다 다르므로 추상 메소드로 선언한다. hotwater, putCup 메소드는 서브클래스로 공통으로 쓰기때문에 부모 클래스에 정의하였다. Coffee, Tea 클래스는 make 메소드를 내부에서 정의하고 알고리즘의 다른 부분들(putCoffee, putTea / putSugar, putLemon)은 서브클래스 내부에서 정의 하였다.

위의 다이어그램을 다시 생각해보자. 사실 putCoffe와 putTea는 만드는 과정 중 뜨거운 물에 넣는다는 의미에서 같은 맥락이고, addSugar, addLemon는 만들어진 음료 위에 무엇을 넣는것에서 같은 맥락이다.
따라서 putCoffee와 putTea를 putSomething, addSugar, addLemon을 addItem 으로 대체해보자. (조금 어거지다)
public class Beverage {
final void make() {
hotWater();
putSomething();
putCup();
addItem();
}
abstract void putSomething();
abstract void addItem();
void hotWater{
// 물을 끓인다.
}
void putCup{
// 커피를 컵에 넣는다
}
}
public class Coffee extends Beverage{
public void putSomething{
// 커피를 넣는다.
}
public void addItem{
// 설탕을 넣는다.
}
}
public class Tea {
public void putSomething{
// 차를 넣는다.
}
public void addItem{
// 레몬을 넣는다.
}
}
지금까지 한 것이 템플릿 메소드 패턴이라 할 수 있다.
Beverage의 make가 캡슐화된 알고리즘이 되며, 템플릿 메소드에서는 알고리즘의 각 단계들을 정의하며 한 개 이상의 알고리즘 단계가 서브클래스에 의해 제공될 수 있다.
처음 만든 클래스와 템플릿 메소드를 사용한 경우를 비교하면 아래표와 같다.

어댑터 패턴과 퍼사드 패턴
해외 여행을 하다보면 오른쪽과 같은 전기 꼽는데가 있고 한국에서 220v 충전기를 쓰려면 왼쪽과 같은 어댑터를 사용해야 한다.


IT 측면에서 보면, 이미 개발되어 있는 시스템이 있는데 새로운 제품과 통신하는 과정에서 서로의 인터페이스가 다를 수 있다. 개발된 시스템을 바꿀수도 있지만, 이를 그대로 두고 중간에 인터페이스를 맞춰주는 모듈이 있다고 하면 이를 어댑터라고 할 수 있다.
어댑터 패턴이란, 한 클래스의 인터페이스를 클라이언트에서 사용하고자 하는 다른 인터페이스로 변환하는 것.
퍼사드 패턴이란, 서브시스템의 정의된 다양한 인터페이스들을 어떤 기준으로 묶어 고 수준 인터페이스를 제공하여 쉽게 사용하도록 하는 것.
가령 식사를 한다고 가정하자 아래와 같이 식사에 대한 3가지 기능이 있다고 할 때, 이를 하나로 묶어 하나의 인터페이스로 3가지 기능을 수행한다면 퍼사드 패턴이라고 할 수 있다.
1. 음식을 만든다
2. 밥을 먹는다
3. 설거지를 한다.
퍼사드/어댑터/데코레이션 패턴의 차이를 간단히 설명하면 아래와 같다.
퍼사드 - 인터페이스를 간단하게 바꿈
어댑터 - 한 인터페이스를 다른 인터페이스로 변환한다.
데코레이션 - 인터페이스는 두고 책임만 추가
커맨드 패턴
객체지향 모델링은 실 세계를 모델링 하는 것 처럼 소프트웨어를 모델링 하는 것.
레스트토랑을 생각해보면 손님이 들어와 주문서를 작성하면, 웨이터는 주문서를 받아 주방으로 전달한다. 웨이터 입장에선 주문을 받아 그대로 주방으로 전달하면 되기 때문에 고객이 어떤 주문을 했는지 주방에서 어떤 요리를 만드는지는 전혀 신경 쓸 필요가 없다.
커맨드 패턴이란, 요구사항을 객체로 캡슐화 할 수 있는 디자인 패턴으로 작업을 요청한 쪽과 처리하는 쪽을 분리할 수 있다.
집안에서 공용으로 쓰는 리모콘이 있다고 가정하자. 이 리모콘을 통해 문을 열고 닫을 수 있으며, 불을 키고 끌수있고, 커튼을 열고 닫을 수 있다. 여기서 요구사항은 리모콘을 통해 요청되는 작업들이며 이 작업들을 캡슐화하여 요청작업과 실행작업을 분리시킨다.
간단한 예로 불을 켜는 리모콘 소스를 보자. (예시를 위한 코드지, 실제 동작하지 않음)
Command 인터페이스를 구현한 클래스(여기선 LightOnCommand)들이 실행작업을 구현하며, 요청작업은 SimpleRemoteControl의 setCommand를 호출한 쪽에서 명령을 요청하므로 커맨드 패턴처럼 분리된 걸 알 수 있다.
위 구조로 확장을 하자. 불을 켜고 끄고, 문을 열고 닫고, 에어콘을 키고 끄는 형태를 다이어그램으로 보면 아래와 같다.
집 주인의 다양한 요청(불, 에어콘, 문, 커튼 등등)의 구현은 Command 인터페이스를 구현하는 클래스들에서 맡고 있다. 요청은 SimpleRemoteControl 클래스에서 SetCommand로 수행한다. SimpleRemoteControl은 집 주인의 요청에 대해 신경쓸필요가 없으며 execute()로 실제 어떤 행동이 수행되는지 알 필요가 없다.

레스트토랑을 생각해보면 손님이 들어와 주문서를 작성하면, 웨이터는 주문서를 받아 주방으로 전달한다. 웨이터 입장에선 주문을 받아 그대로 주방으로 전달하면 되기 때문에 고객이 어떤 주문을 했는지 주방에서 어떤 요리를 만드는지는 전혀 신경 쓸 필요가 없다.
커맨드 패턴이란, 요구사항을 객체로 캡슐화 할 수 있는 디자인 패턴으로 작업을 요청한 쪽과 처리하는 쪽을 분리할 수 있다.
집안에서 공용으로 쓰는 리모콘이 있다고 가정하자. 이 리모콘을 통해 문을 열고 닫을 수 있으며, 불을 키고 끌수있고, 커튼을 열고 닫을 수 있다. 여기서 요구사항은 리모콘을 통해 요청되는 작업들이며 이 작업들을 캡슐화하여 요청작업과 실행작업을 분리시킨다.
간단한 예로 불을 켜는 리모콘 소스를 보자. (예시를 위한 코드지, 실제 동작하지 않음)
public interface Command {
public void execute();
}
public class LightOnCommand implements Command {
Light light;
public LightOnCommand(Light light) {
this.light = light;
}
public void execute() {
light.on();
}
}
public class SimpleRemoteControl {
Command slot;
public SimpleRemoteControl() {}
public void setCommand(Command command) {
slot = command;
}
public void putButton() {
slot.execute();
}
}Command 인터페이스를 구현한 클래스(여기선 LightOnCommand)들이 실행작업을 구현하며, 요청작업은 SimpleRemoteControl의 setCommand를 호출한 쪽에서 명령을 요청하므로 커맨드 패턴처럼 분리된 걸 알 수 있다.
위 구조로 확장을 하자. 불을 켜고 끄고, 문을 열고 닫고, 에어콘을 키고 끄는 형태를 다이어그램으로 보면 아래와 같다.
집 주인의 다양한 요청(불, 에어콘, 문, 커튼 등등)의 구현은 Command 인터페이스를 구현하는 클래스들에서 맡고 있다. 요청은 SimpleRemoteControl 클래스에서 SetCommand로 수행한다. SimpleRemoteControl은 집 주인의 요청에 대해 신경쓸필요가 없으며 execute()로 실제 어떤 행동이 수행되는지 알 필요가 없다.

싱글톤 패턴
개발하다 보면 싱글톤 이라는 말을 종종 듣곤한다.
싱글톤 패턴이란, 클래스의 객체는 오직 하나만 만들어지고 어디서든 그 객체에 접근할 수 있어야 한다.
아래 코드는 싱글톤의 예이다. 주목할 부분은 생성자인데, private로 선언했기 때문에 singeton class 내부에서만 인스턴스를 생성할 수 있다. 인스턴스를 생성하는 주체는 오직 자기 자신이며, 한번 만들어지면 if문에 따라 존재하는 인스턴스를 반환하기 때문에 두번 이상 생성될 수 없다. 또한 public getInstance 메소드를 통해 어디서든 singleton 인스턴스를 받을 수 있다.
스레드 A,B가 있다고 할때 위 코드를 실행하는 순서가 아래와 같은 흐름을 탄다고 하자.
1. 스레드 A가 if(only_one_instance == null) { 구문을 수행하였다.
2. 스레드 B가 cpu time을 얻어 f(only_one_instance == null) { 구문을 수행하였다.
3. 스레드 B가 only_one_instance = new singleton(); 구문을 수행하여 instance를 생성했다. 4. 스레드 A가 cpu time을 얻어 only_one_instance = new singleton(); 구문을 수행하여 instance를 생성했다.
위와 같은 흐름으로 수행되면 인스턴스가 2개가 생성되어 예상치 못한 결과를 얻을 수 있다. 책에서는 위 현상을 막기 위해 3가지 정도의 방법을 제안했다.
1. if문으로 인스턴스를 체크하여 생성하는 로직에 lock을 걸어 스레드를 동기화 하는 방법
2. 내부 클래스 인스턴스 (only_one_instance)를 선언과 동시에 초기화하는 방법
3. volatile 키워드를 사용하여 멀티스레딩 환경에서도 안전하게 사용하는 방법
- private volatile static singleton only_one_instance;
싱글톤 패턴이란, 클래스의 객체는 오직 하나만 만들어지고 어디서든 그 객체에 접근할 수 있어야 한다.
아래 코드는 싱글톤의 예이다. 주목할 부분은 생성자인데, private로 선언했기 때문에 singeton class 내부에서만 인스턴스를 생성할 수 있다. 인스턴스를 생성하는 주체는 오직 자기 자신이며, 한번 만들어지면 if문에 따라 존재하는 인스턴스를 반환하기 때문에 두번 이상 생성될 수 없다. 또한 public getInstance 메소드를 통해 어디서든 singleton 인스턴스를 받을 수 있다.
public class singleton {
private static singleton only_one_instance;
private singleton() {}
public static singleton getInstance() {
if(only_one_instance == null) {
only_one_instance = new singleton();
}
return only_one_instance;
}
}
스레드 A,B가 있다고 할때 위 코드를 실행하는 순서가 아래와 같은 흐름을 탄다고 하자.
1. 스레드 A가 if(only_one_instance == null) { 구문을 수행하였다.
2. 스레드 B가 cpu time을 얻어 f(only_one_instance == null) { 구문을 수행하였다.
3. 스레드 B가 only_one_instance = new singleton(); 구문을 수행하여 instance를 생성했다. 4. 스레드 A가 cpu time을 얻어 only_one_instance = new singleton(); 구문을 수행하여 instance를 생성했다.
위와 같은 흐름으로 수행되면 인스턴스가 2개가 생성되어 예상치 못한 결과를 얻을 수 있다. 책에서는 위 현상을 막기 위해 3가지 정도의 방법을 제안했다.
1. if문으로 인스턴스를 체크하여 생성하는 로직에 lock을 걸어 스레드를 동기화 하는 방법
2. 내부 클래스 인스턴스 (only_one_instance)를 선언과 동시에 초기화하는 방법
3. volatile 키워드를 사용하여 멀티스레딩 환경에서도 안전하게 사용하는 방법
- private volatile static singleton only_one_instance;
팩토리 패턴
* Simple factory
kimbob 가게를 생각해보자. 주문을 하면 김밥객체를 받아 재료를 준비하고 만들고 돌돌말아 자른뒤 포장한다고 가정해보자. 이를 코드로 보면 아래와 같다.
Kimbob orderKimbob() {
Kimbob kimbob = new Kimbob();
kimbob.prepare();
kimbob.make();
kimbob.roll();
kimbob.cut();
kimbob.box();
}
Kimbob orderKimbob(String type) {
Kimbob kimbob;
if(type.equals("normal")) {
kimbob = new Kimbob();
}
else if(type.equals("tuna")) {
kimbob = new TunaKimbob();
}
else if(type.equals("kimchi")) {
kimbob = new KimchiKimbob();
}
Kimbob kimbob = new Kimbob();
kimbob.prepare();
kimbob.make();
kimbob.roll();
kimbob.cut();
kimbob.box();
}제일 중요한 디자인 원칙 중 하나는 변경되는 부분을 변경되지 않는 부분과 분리하여 캡슐화 하는 것이다. 위 예를 보면 변경되는 부분은 김밥 객체를 받는 부분이다. 일단 객체만 받으면 준비,만들기,말기,자르는 기능들은 변하지 않는다.
그럼 위에서 변경되는 부분을 factory라는 객체로 캡슐화 시켜보자
public class SimpleKimbobFactory {
public Kimbob createKimbob(String type) {
Kimbob kimbob = null;
if(type.equals("normal")) {
kimbob = new Kimbob();
}
else if(type.equals("tuna")) {
kimbob = new TunaKimbob();
}
else if(type.equals("kimchi")) {
kimbob = new KimchiKimbob();
}
return kimbob
}
}
이렇게 변경할 경우 무엇이 좋은거지? 궁금증이 들 수 있다. kimbob 객체의 생성을 배달, 가격, 설명 등의 기능에서 필요하다고 하면, factory로 캡슐화한 클래스만 변경하면 된다.
* factory 메소드 패턴
위의 김밥집이 잘되어 중국과 일본에도 진출되었다고 생각해보자. 기존의 simple factory를 제거하고 아래와 같이 factory를 만들 수 있다.
ChinaKimbobFactory cFactory = new ChinaKimbobFactory();
KimbobStore chinakimbobStore = new KimbobStorecFactory();
chinakimbobStore.orderKimbob('tuna');
JapanKimbobFactory jFactory = new JapanKimbobFactory();
KimbobStore japankimbobStore = new KimbobStorecFactory();
japankimbobStore.orderKimbob('kimchi');
이렇게 적용해보니 나라마다 만드는 방식이 조금씩 달라 문제가 발생했다. (책에서 이와 같은 형식으로 설명하는데 뭐가 문제인지 잘 이해가 안간다 똑똑하고 싶어...)
이때 김밥을 만드는 활동은 KimbobStore 클래스에 국한시키면서, 나라마다 고유의 스타일을 살릴 수 있는 방법이 있다. factory 패턴을 적용하는 것이다. 정의는 뒤에서 하고 먼저 아래를 보자.
createKimbob 메소드를 kimbobStore에 다시 집어놓고 추상메소드로 선언한다. 각 나라에서는 고유의 스타일에 맞게 메소드를 정의할 것이다.
public abstract class KimbobStore{
public Kimbob orderKimbob(String type) {
Kimbob kimbob;
kimbob = createKimbob(type);
kimbob.prepare();
kimbob.make();
kimbob.roll();
kimbob.cut();
kimbob.box();
return kimbob;
}
protected abstract Kimbob createKimbob(String type);
}
팩토리 메소드 패턴에서는 객체의 생성을 캡슐화 한다. 그리고 서브 클래스에서 어떤 객체를 만들지를 결정한다.
위의 Simple factory 부터 정리해보면 객체의 생성이 변경되는 부분일 때, 이를 캡슐화하고 어떤 객체가 만들어질지는 서브클래스에서 결정하게 되면 factory 메소드 패턴을 쓴다고 볼 수 있다.
데코레이터 패턴
케익 데코레이터 라고 한다면, 케익 위에 다양한 장식들로 케익을 꾸미는 것을 의미한다. 여기서 장식물을 뺸 케익 자체는 변경되지 않는다.
소프트웨어 디자인 패턴의 데코레이션이란, 객체의 기능을 유연하게 확장할 수 있는 방법을 제공한다.
데코레이션 패턴은 OCP(open-closed principle) 원칙을 따른다.
OCP란 클래스 확장은 열려있고 코드 변경에 대해서는 닫혀 있어야 한다는 것이다.
OCP 원칙 자체는 좋아보이지만, 이를 적용시키기 전 충분함 검토가 필요하다. 무조건 OCP를 적용시키면 쓸데없이 복잡해지고 시간이 들 수 있다.
이론적으로 뭉뚱그리면 어렵지않은데, 어찌 자세히 들어갈수록 잘 이해가안되 comment만 하고 넘어간다.
소프트웨어 디자인 패턴의 데코레이션이란, 객체의 기능을 유연하게 확장할 수 있는 방법을 제공한다.
데코레이션 패턴은 OCP(open-closed principle) 원칙을 따른다.
OCP란 클래스 확장은 열려있고 코드 변경에 대해서는 닫혀 있어야 한다는 것이다.
OCP 원칙 자체는 좋아보이지만, 이를 적용시키기 전 충분함 검토가 필요하다. 무조건 OCP를 적용시키면 쓸데없이 복잡해지고 시간이 들 수 있다.
이론적으로 뭉뚱그리면 어렵지않은데, 어찌 자세히 들어갈수록 잘 이해가안되 comment만 하고 넘어간다.
옵저버 디자인 패턴
옵저버 디자인 패턴
옵저버 패턴은 신문으로 예를 들어보자. 신문의 출판사와 구독자가 있을 것이다.
출판사는 신문을 출판하고, 구독자는 출판사에 구독 신청을 하면 신문이 나올때마다 해당 신문을 배달받을 수 있다. 구독자로 있는 한, 신문이 나올때 마다 구독할 수 있다.
신문을 구독하고 싶지 않으면 해지를 신청하고, 더 이상 신문이 나와도 구독받지 않는다.
옵저버 패턴에서 출판사를 주제, 구독자를 옵저버라고 부른다.
주제의 데이터가 달리지면 등록한 옵저버들에 대해 소식이 전해진다.
옵저버 패턴의 정의는 한 객체의 상태가 바뀌면, 그 객체에 의존하는 다른 객체들에게 자동으로 내용이 갱신되는 일대다 의존성을 정의한다.
아래를 보자.
인터페이스 Subject를 구현하는 주제(NewsSubject)와 Observer 인터페이스를 구현하는 NewsObserverA와 NewsObserverB가 있다.
주제(NewsSubject)는 옵저버들을 추가/삭제하는 registerObserver와 removeObserver 메소드를 구현하며, 데이터가 변경될 경우 옵저버에게 알리는 notifyObserver 메소드를 구현한다. 주제의 데이터가 변경될 경우 Observer 인터페이스를 구현하는 모든 클래스들은 update 메소드를 통해 변경된 데이터를 다룰 수 있다.
아래를 보자.
인터페이스 Subject를 구현하는 주제(NewsSubject)와 Observer 인터페이스를 구현하는 NewsObserverA와 NewsObserverB가 있다.
주제(NewsSubject)는 옵저버들을 추가/삭제하는 registerObserver와 removeObserver 메소드를 구현하며, 데이터가 변경될 경우 옵저버에게 알리는 notifyObserver 메소드를 구현한다. 주제의 데이터가 변경될 경우 Observer 인터페이스를 구현하는 모든 클래스들은 update 메소드를 통해 변경된 데이터를 다룰 수 있다.

아래 코드는 실제로 동작하진 않지만 위 클래스 구성도를 구현하면 이렇다 라는 개념으로 코딩하였다.
Subject 인터페이스를 정의하고, NewsSubject class가 구현하도록 하였다. NewsSubject는 각 옵저버들을 추가/삭제하는 기능을 구현하고 데이터 변경 시, 각 옵저버들의 update 함수를 호출함으로써 옵저버 패턴을 구현할 수 있다.
public interface Subject {
public void registerObject(Observer o);
public void removeObject(Observer o);
public void notifyObject();
}
public class NewsSubject implements Subject {
private ArrayList observers;
private int news;
public void registerObject(Observer o) {
Observer.add(o);
}
public void removeObject(Observer o) {
Observer.remove(o);
}
public void notifyObject() {
for(int i=0; i<observers.size(); i++) {
Observer observer = (Observer)observers.get();
observer.update(news);
}
}
public void makeNews(int news) {
this.news = news;
notifyObject();
}
}
아래는 Observer 인터페이스를 선언하고 NewsObserverA 클래스에서 Observer를 구현하였다. NewsSubject 주제가 makeNews를 통해 새로운 신문을 출판하면 각 옵저버의 update(news) 함수를 호출하고,
옵저버는 해당 데이터를 수신하여 자신이 원하는 일을 할 수 있다.
public interface Observer {
public void update(int news);
}
public class NewsObserverA implements Observer {
private int news;
private Subject newsSubject;
public NewsObserverA(Subject newsSubject) {
this.newsSubject = newsSubject;
}
public void update(int news) {
this.news = news;
// do somethig by news
}
}
느슨한 결합 (loose coupling)
두 객체가 느슨하게 결합되어 있다는 건, 둘의 상호작용을 서로가 잘 모른다는 의미
옵저버 패턴에서는 주제와 옵저버가 서로 느슨하게 결합 됨
왜그럴까?
- 주제가 옵저버에 대해 하는건 특정 인터페이스(Observer)를 구현한다는 것만 알고있음
- 옵저버는 언제든지 새로 추가될 수 있다. 추가 된 Observer는 Observer 인터페이스만 구현하면 주제를 전혀 변경할 필요가 없다.
스트래티지 패턴 (Strategy Pattern)
스트래티지 패턴이란.. 기능을 정의하고 변경되는 부분을 캡슐화하여 교환해서 사용하는 패턴... 말로는 어려우니 아래를 보자.
Dog라는 부모클래스를 Japan, korea dog에서 상속받고 있다.
모든 개들은 walk (걸음) 속성을 지니고 있으므로 부모 class인 Dog에 구현하고, 외형(display)은 모두 다르므로 Dog에 추상 메소드로 정의하고 자식 클래스들이 오버라이딩 하고 있다.




Dog라는 부모클래스를 Japan, korea dog에서 상속받고 있다.
모든 개들은 walk (걸음) 속성을 지니고 있으므로 부모 class인 Dog에 구현하고, 외형(display)은 모두 다르므로 Dog에 추상 메소드로 정의하고 자식 클래스들이 오버라이딩 하고 있다.

이 때, japan dog에 run (달리는) 기능이 필요해 부모 Dog 클래스에서 구현하고 자식 클래스들이 상속받았다.

하나 문제가 생겼다. 한국개들은 달리는 속도가 다른데 부모 클래스의 run 메소드를 그대로 상속 받는 점이였다. korea Dog 클래스에 run 함수를 오버라이딩 하여 처리하도록 하였다.

문제는 다음과 같은 가정에서 발생한다. 만약 전 세계의 개들을 객체로 만드는 일이 필요하다. 개들마다 속도가 다르다면 하위 클래스의 run 함수 전부를 오버라이딩 할 것 인가? 가능은 하지만 이 방법은 객체지향의 장점을 잘 활용할 수 없다고 본다.
strategy 패턴은 변경되는 부분을 캡슐화하고 객체들간 교환을 통해 디자인하는 패턴이다.
strategy 패턴의 디자인 원칙을 보자면 아래와 같다.
1. 프로그램의 변경되는 부분을 찾아내고 변경되지 않는 부분으로부터 분리한다.
2. 상속보다는 구성을 활용한다.
위 예제로 돌아가보면, 변경되는 부분은 무엇인가? run 기능이다. 이 기능을 변하지 않는 다른 기능들과 분리시켜야 한다. 또한 상속을 배제하고 인터페이스를 통해 접근하도록 한다.
Dog 클래스는 인터페이스 변수 하나를 두는 것으로 더 이상 run에 대한 기능은 신경쓰지 않아도 된다.

{kind=link}
위 그림을 코드로 표현해보자. 우선 인터페이스 부분은 아래와 같다.
interface DoRun {
public void run();
}
class fast implements DoRun {
public void run() {
System.out.println("빠름");
}
}
class slow implements DoRun {
public void run() {
System.out.println("느림");
}
}
class koreaDog extends Dog {
public koreaDog() { dorun = new fast(); }
void display() {
System.out.println("한국개생김새");
}
}
class japanDog extends Dog {
public japanDog() { dorun = new slow(); }
void display() {
System.out.println("일본개생김새");
}
}
public abstract class Dog {
DoRun dorun;
public Dog() {}
public void walk() {
System.out.println("모든 개는 걸어요");
}
public void performRun() {
dorun.run();
}
abstract void display();
public static void main(String[] args) {
Dog dog = new japanDog();
dog.display();
dog.performRun();
dog = new koreaDog();
dog.display();
dog.performRun();
}
}
정리를 해보자. 스트래티지 패턴이란, 객체마다 달라지는 부분은 오버라이딩으로 처리하기 보단, 변경되는 부분을 변경되지 않는 부분과 나누고 인터페이스를 선언해 객체간의 교환을 통해 문제를 해결하는 디자인 패턴이라 생각하면된다.
레퍼런스
- Head First 디자인패턴
구글 블로거에 소스 코드 삽입
구글링을 통해 찾은 방법들을 적용시켜 보니 전부 실패..
찾은 글들마다 방법을 시도하던 중 아래글에서 소스 코드 삽입에 성공하였다
별것도 아닌데 힘들다
<pre><code class="언어명">
~~~~~~~~~~
</code></pre>
참조 : http://koonhous.blogspot.com/2017/07/highlight-source.html
찾은 글들마다 방법을 시도하던 중 아래글에서 소스 코드 삽입에 성공하였다
별것도 아닌데 힘들다
<pre><code class="언어명">
~~~~~~~~~~
</code></pre>
참조 : http://koonhous.blogspot.com/2017/07/highlight-source.html
OOP(Object-Oriented Programming), 객체지향 프로그래밍이란
객체지향 프로그래밍에 대해
최근 회사에서 python으로 개발을 하고있다.
python 언어를 처음 써본지라, 공부할게 많고 OOP를 잘 모르는 지라 절차지향 프로그래밍으로 개발을 했는데... 최종적으로는 OOP 개발을 하기 위해 공부하는 과정에서 아래 글을 끄적여 본다.
python 언어를 처음 써본지라, 공부할게 많고 OOP를 잘 모르는 지라 절차지향 프로그래밍으로 개발을 했는데... 최종적으로는 OOP 개발을 하기 위해 공부하는 과정에서 아래 글을 끄적여 본다.
객체지향 프로그래밍
- 실제 세계를 모델링 하는 방식으로 프로그래밍 하는 방법
- 데이터, 기능을 하나의 클래스로 정의하고 객체를 생성하며, 이런 객체들의 상호작용을 통해 프로그래밍 한다
객체지향 특징
- 추상화
- 객체의 모든 정보가 아닌, 필요한 데이터와 기능을 정의하는 것
- 노트북을 객체로 정의할떄, 노트북의 모든 기능을 뽑아서 정의하는 것이 아니라 필요로한 데이터와 기능만을 추려서 정의하는것을 추상화라한다.
- 캡슐화
- 객체의 데이터를 공용 메소드를 통해서만 변경하도록 하는 방법 (데이터 캡슐화)
- 캡슐화와 정보은닉은 동일한 개념이 아님
- 정보은닉은, 복잡하거나 변경가능한 설계 개념을 안전한 인터페이스 뒤로 숨기는 설계원리로 정보은닉의 목적은 변경의 유연성을 제공하는 것이다.
- 상속
- 부모(상위)의 개념을 자식(하위)이 그대로 물려받는 것
- 왜 쓰는가? 코드의 재사용과 확장을 쉽게 하기위해서
- Parent 라는 부모 클래스가 있다고 하자. Child라는 Parent의 자식 클래스는 Parent가 만들어놓은 기능을 그대로 물려받을 수 있다. (코드의 재사용)
- Parent의 기능을 Child에서 기능 변경없이 확장할 필요가 있다고 하자. 오버라이딩을 통해 Parent 기능은 그대로 유지하고 확장할 부분만 Child에서 구현하면 된다. (확장)
- 다형성
- 하나의 객체의 기능이 다양한 객체의 기능을 수행하는 것
- 왜 쓰는가? 코드의 간결함과 라인 수를 줄일 수 있다. 객체를 매개변수로 받는 함수 A가 있다고 하자. 이 함수를 여러 객체가 사용한다고 한다면, 객체 수만큼 함수를 정의해야 한다. 하지만 다형성을 통해 하나의 객체가 여러 객체의 타입을 받을 수 있으므로 불필요한 중복 코드를 제거할 수 있다.
- 다형성은 상속과 인터페이스로 구현가능하다. 상속의 경우 부모 클래스가 여러 자식 클래스들의 객체를 가리킬 수 있으며, 인터페이스 역시 자신의 메소드를 구현하는 모든 클래스를 가리킬 수 있다.
- 추상 클래스와 인터페이스?
- 추상 클래스는 하나 이상의 추상 메소드를 가진 클래스.
- 추상 메소드란, 메소드의 정의만 선언한 후, 구현은 자식클래스에게 맡긴다.
- 인터페이스는 모든 메소드가 추상 메소드로, 모든 메소드의 기능은 구현을 하는 클래스에게 위임한다.
레퍼런스
프로그래밍 패러다임
프로그래밍 패러다임과 특징
프로그래밍 패러다임
- 프로그래밍 관점, 프로그램을 설계 및 개발하는 방법론
- 절차지향 / 객체지향 / 함수형 프로그래밍 기법등이 있다.
절차지향 프로그래밍
- 절차란, 일반적인 의미의 절차(순서)가 아닌 함수나 프로시저를 의미한다.
- 코드 재사용을 위해 함수(프로시저)를 정의하여 사용한다.
객체지향 프로그래밍
- 데이터와 기능을 하나의 class로 묶어 객체를 생성하여 표현하는 방법
- 객체지향의 특징(추상화, 캡슐화, 다형성, 상속)을 잘 활용하면 코드 재사용과 유지보수가 좋다.
함수형 프로그래밍
- 람다 대수를 기반으로 시작된 프로그래밍
- 변경가능한 전역변수들을 변경 불가하도록 하여 부수효과(side effect)를 없애는 장점
프로그래밍 패러다임과 언어
- 하나의 언어에도 여러 프로그래밍 관점(패러다임)으로 개발가능
- C++로도 절차/객체 지향 프로그래밍이 가능하며, python으로도 절차/객체/함수형 프로그래밍이 가능하다.
피드 구독하기:
덧글 (Atom)